License Plate Recognition
We are investigating the best models/algorithms for license plate detection.
View the Project on GitHub sauravghosal/license-plate-recognition
Introduction/Background
When it comes to license plate recognition in machine learning, there exists a number of popular object detection models. With newer advancements in the object detection methods such as YOLO it has become renowned for its speed and accuracy, however, we would like to investigate and compare the pros and cons of popular models and hope to gain insight on the best model in a particular scenario. For instance, prior research by Girshick et al.1 and Redmon et al.2 indicates that the YOLO algorithm performs faster but not as accurately as Fast R-CNN at object detection. Although the current approaches work well, it is important to continue assessing the different models and consider which model is best for specific scenarios.
Problem definition
There have been many object detection algorithms with the advancement of Computer Vision technologies. When it comes to license plate recognition in machine learning, there already exists a number of papers using various methods to correctly identify the plates such as Naive Bayes, KNN, CNN, and YOLO. For instance, prior research by Girshick et al.1 and Redmon et al.2 indicates that the YOLO algorithm performs faster but not as accurately as Fast R-CNN at object detection. Although the current approaches work well, it is important to continue assessing the different models and consider which model is best for specific scenarios. Our project aims to compare these methods and find which method works best when it comes to license plate recognition.
Data Collection
We have collected multiple datasets from dataset1, dataset2, dataset3, dataset4, and dataset 5 consisting of approximately 2,151 car images with labels of ‘xmin’, ‘ymin’, ‘xmax’, and ‘ymax’ denoting the bounding box of the license plate. Our current goal is to combine the individual datasets into a uniform set and then perform data augmentation to get more than 4,353 sets of labeled images.
Data Preprocessing
Because our dataset is a combination of various datasets, we needed a uniform class name for a collective dataset. We altered each dataset’s xml annotations to have the name ‘LP’ denoting license plate which will help later in the YOLO and R-CNN models. We also transformed our first dataset from a csv to a xml format. In the collective dataset, each annotation and image is denoted by a unique number. In addition, there were many images in our dataset that had more than one license plate but not all of the license plates had a bounding box thus we had to add bounding boxes to those images with multiple license plates.
Methods
There are many object detections algorithms available and we want to investigate their special qualities. For license plate detection, the You Only Look Once (YOLO) model has been the recent popular model for quick image object detection. Previously, before YOLO, convolutional neural networks (CNN) was the most widely adopted method among object detection. Using different models, we are looking to compare them and examine their properties with regards to object detection. By comparing their properties we are aiming to find the most optimal model for a particular scenario. In addition, by investigating models such as CNN and YOLO we are looking to unveil neural network properties that might allow us to create a mesh of both models which in turn could allow us to create our own combination of the models.
Results
1. You Only Look Once v5 (YOLOv5)
1.1 What is YOLOv5
YOLO is an algorithm that does a single pass over an image and splits the image into a grid system and uses neural networks to provide real-time object detection for each cell. Because of this technique, the YOLO algorithm has gained popularity because of its speed and accuracy over previous object detection predecessors as they were not able to detect objects in a single algorithm run.
The difference of YOLOv5 with other versions is this version utilizes PyTorch instead of Darknet like other versions. It is extremely fast and lightweight than other YOLO versions, while the accuracy is on par with YOLOv4 or other benchmarks. YOLOv5 uses leaky ReLU and sigmoid activation, ADAM and SGD as its optimizer options, and binary cross-entropy as its loss function. Furthermore, YOLOv5 automatically augments the images as it’s taken in by performing a number of augmentations such as:
- Mosaic and self-adversarial training (SAT)
- Random horizontal flip
- Albumentations
- Augment HSV
- Random affine (rotation, scale, translation, shear)
1.2 Learnings from YOLOv5 training
The following three training examples highlight important changes to our dataset throughout our testing phase that lead to improvements to our license plate detection model. The first training was our baseline of no additional augmentations, the second training example showed the best mixture of augmentations which tackled issues in training one, and finally the third example shows additions to our dataset that tackled issues in training two.
One thing to note about our confusion matrix is that it shows a 100% rate of detecting false positives for all our models; however, we believe the cause of this is that there are no labels for “background,” thus there is no value for true negatives. In addition our Precision and Recall values reflect that our false positive rates are improving even though our confusion matrix does show that aspect.
1.2.1 Training 1
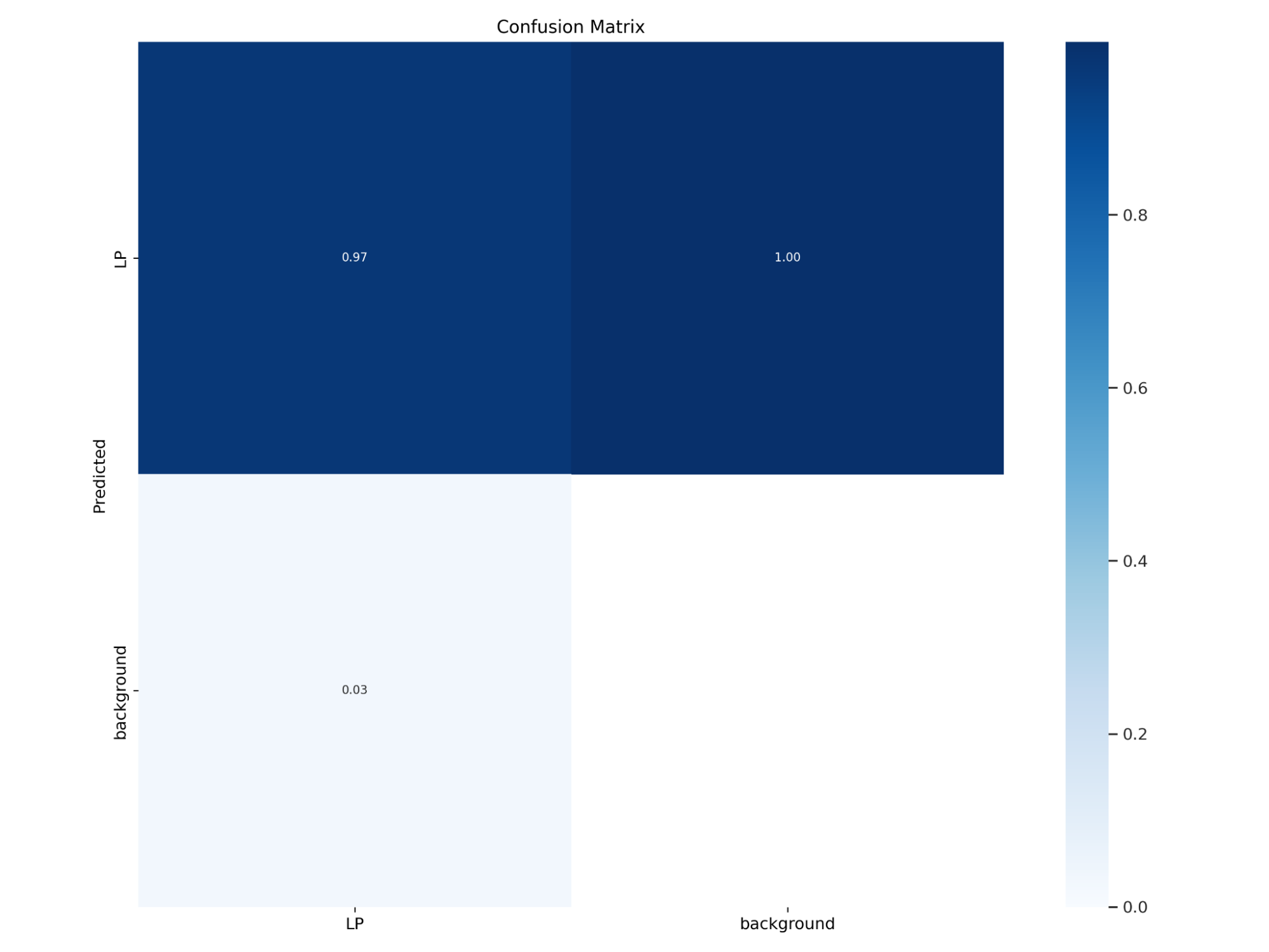
With no additional augmentations to the images besides the built in image augmentations in YOLOv5 the trained model had a 97% mAP. However, when testing the trained model on unseen images the model would detect a high number of false positives in the images. Some examples of these false positives would be timestamps on images and some more difficult objects to discern from license plates because of their similarities such as a bus’s sign, bumper stickers, and street signs.
1.2.2 Training 2
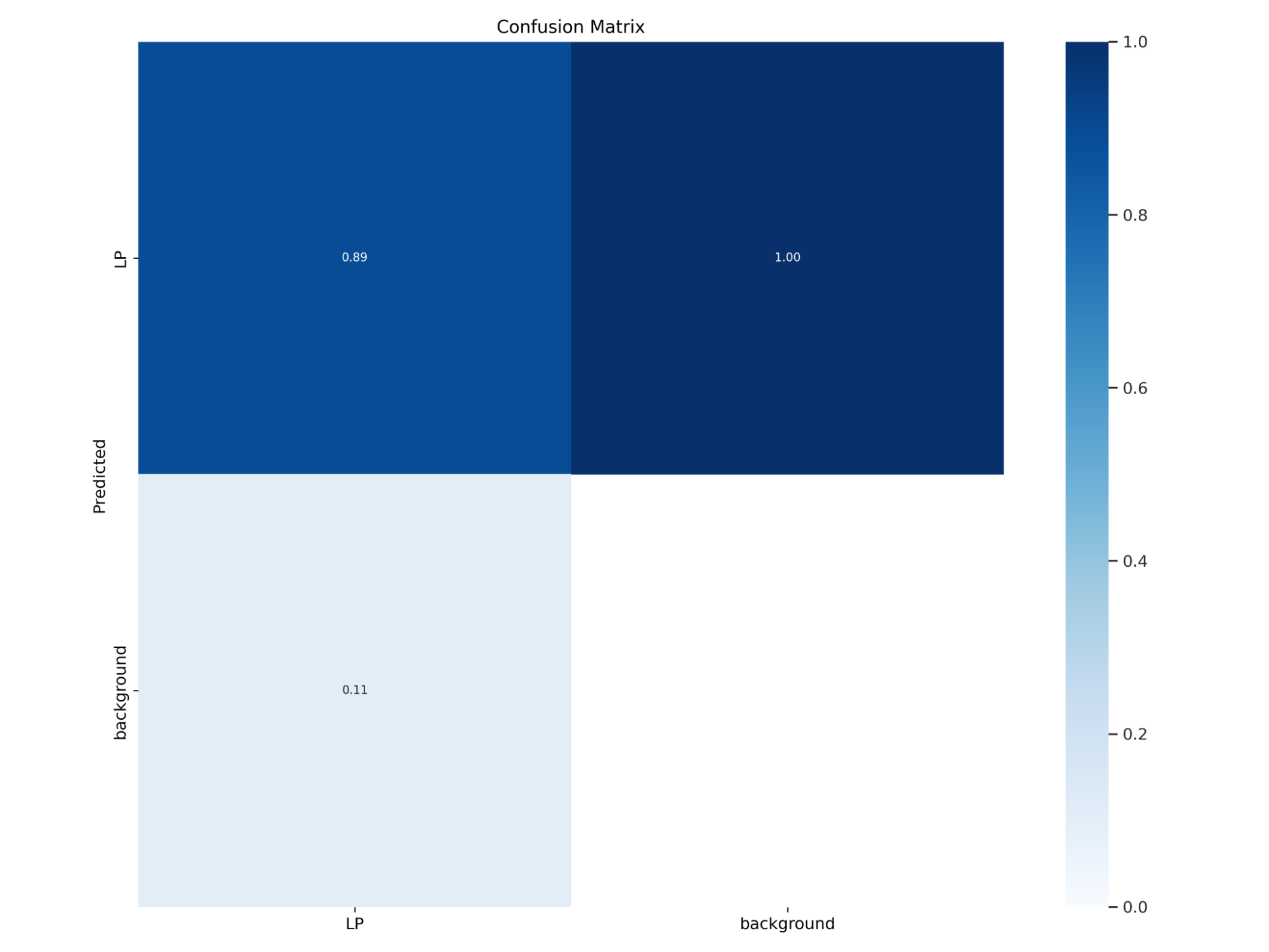
For this training run we added additional augmentations listed above to our dataset beforehand. The resulting mAP for this model was 89%. Testing this model on unseen images we started detecting less of the obvious objects in the images that were not license plates such as timestamps in for an image, and saw a slight decrease in detecting similar objects to license plate objects such as a bus’s sign, bumper stickers, and signs.
1.2.3 Training 3
For our final model we kept the same augmentations as training two but for this training we added ‘background images’ to our dataset which are images that do not contain any labels. The purpose of these background images are to reduce false positives so we chose background images that consisted of a mixture of buses with window signs, street signs, and bumper stickers. The resulting mAP for the final model is 91% and saw a greater reduction in objects with similarities to license plates especially bus signs and street signs however it still struggled with some bumper stickers.
| Training 1 | Training 2 | Training 3 | |
|---|---|---|---|
| Additional Augmentations | None | Flip: Vertical, Grayscale: 70% of images, Blur: Up to 1px, Noise: Up to 2% of pixels, Cutout: 3 boxes with 4% size each | Flip: Vertical, Grayscale: 70% of images, Blur: Up to 1px, Noise: Up to 2% of pixels, Cutout: 3 boxes with 4% size each |
| mAP | 98% | 89% | 91% |
| Precision | 97% | 92.1% | 95.2% |
| Recall | 95% | 84.7% | 87.3% |
1.3 Results for YOLOv5
Using the best trained model for YOLOv5 we ran inference on unseen images and we predicted that our trained model would have difficulties detecting license plates from the United States because our dataset consisted mostly of license plates from outside the United States however this was not the case. Our model exceeded in detecting most license plates no matter the origin if the license plate was close or midrange from the camera. However, our model performed poorly when detecting all license plates in an image, especially smaller license plates that are further in the background. This poor result could be due to the fact that our dataset contained mainly one license plate in the image or that smaller license plates were too small for the model to make a confident prediction. In addition, our model would sometimes confuse bumper stickers as license plates especially if the bumper sticker had a combination of numbers and letters. This confusion can be attributed to the lack of cars with bumper stickers in our dataset for our model to properly differentiate between the two.
2. Faster R-CNN
2.1 What is a Region based Convolutional Neural Network (R-CNN) and Faster R-CNN?
R-CNN is a machine learning model most commonly applied to object detection tasks. It stands for region-based convolutional neural network, applying the concept of region proposals to identify regions of interest before passing in the image into a convolutional neural network.3 To identify regions of interest, the model extracts region proposals by applying an algorithm such as selective search. Selective search proposes regions of interest by grouping together regions of similar pixel density.
Faster R-CNN takes a unified approach to the two steps in the R-CNN task of region proposal and classifier training. Instead of relying on selective search or other region proposal algorithms, Faster R-CNN merges a Region Proposal Network (RPN) and Fast R-CNN into a single network that shares convolutional features.1 The RPN is a fully convolutional network that identifies regions of interest, sharing many features with the detection network, allowing the merging of RPN and Fast R-CNN networks to be possible.
Due to optimizations in the model architecture, Faster R-CNN runs significantly faster than R-CNN; thus, it was the model of choice for this investigation. The model that will be used in this investigation will be the Faster R-CNN model with a ResNet50-FPN backbone provided by PyTorch, pre-trained on COCO dataset to reap the training benefits of transfer learning. The loss function is a combination of the loss from classification and RPN bounding box regression.
2.2 Learnings from Faster R-CNN
Compared to YOLO, the training time for Faster R-CNN was significantly higher, leading the model to timeout during the training phase on Google Colab. Thus, we decided to trim down the number of images in our dataset down to 2,100 images and reduce the number of epochs from 70 to 35. We calculated the mAP, precision, and recall metrics after testing on a set of 420 test images, highlighted below.
| Training 1 | |
|---|---|
| epoch | None |
| mAP | 86.1% |
| Precision | 84.3% |
| Recall | 87.8% |
2.3 Results from Faster R-CNN
Once training was complete on Faster R-CNN, we ran inference on the same set of photos used for the other models. For most images, no matter license plate origin, vehicle model, location of the license plate in the image, or the angle at which the image was taken, the object detection algorithm was able to identify the license plate accurately. The model also identified license plates of vehicles in the background in addition to the main plate in the foreground.
The trained model did have some problems in which it would identify multiple license plates in an image that only contained one, i.e. false positive. In addition, the model would sometimes fail to identify license plates of vehicles in the background; i.e. false negative. Some false positives and false negatives are expected out of any classification algorithm; however, to reduce the number of misclassified license plates and improve model accuracy, we can augment the training data set, add noise to the input data, or introduce regularization into the model.
That being said, from the overall inference and testing results, we can conclude that the Faster-RCNN model performs well at identifying license plates in a given image.
3. Mask R-CNN
3.1 What is Mask R-CNN and how is it different from Faster R-CNN
Mask R-CNN is an extension to the previous model Faster R-CNN and excels more at image segmentation. Image segmentation is the partition of an image into different segments which can be broken further down into semantic segmentation and instance segmentation. Semantic separates the subjects from the background while instance segmentation separates each subject as their own entity.
Unlike Faster R-CNN’s output of 2 for each candidate object, Mask R-CNN outputs a third output which is the object mask. The object mask contains the finer spatial layout of an object. Our implementation of Mask R-CNN actually required a different format for annotations in the form of jsons rather than xml or yolov5.
3.2 Learnings from Mask R-CNN
The following three training results demonstrated poor results despite the many hours it took to train each model with different configurations. The first and two trainings had no additional augmentation but with varying epochs, 30 and 70, while the last training had the same augmentations as yolov5 and epochs of 61. The augmentations are added by the imgaug package and entered as a parameter in the train method.
| Training 1 | Training 2 | Training 3 | |
|---|---|---|---|
| epoch | 30 | 70 | 62 |
| Additional Augmentations | None | None | Flip: Vertical Grayscale: 70% of images Blur: Up to 1px Noise: Up to 2% of pixels Cutout: 3 boxes with 4% size each |
| mAP | 0% | 0% | 0% |
| Precision | 0% | 0% | 0% |
| Recall | 0% | 0% | 0% |
A quick disclaimer is that training was done on Google Colab which is known to have timeout issues once a free account has reached x amount of time using their backend gpu. This made it impossible to continue training on the same account after using all credits and hard to save weights before the runtime terminated all files produced. As a result this could skew the results into underperforming more than yolov5 and Faster R-CNN.
3.3 Results from Mask R-CNN
After training the models for Mask R-CNN, we ran inference with the same photos as YOLOv5 and Faster R-CNN. We expected the metrics gained from Mask R-CNN to be similar to that of Faster R-CNN given that Mask R-CNN is an extension of Faster R-CNN in a sense but the results were extremely disappointing with not a single license plate correctly identified. All models with varying epochs or augmentations did not seem to have a change in loss value as training as much and tended to stay around 1.4 - 1.7.
Some possible explanations for this could be the weights not properly loading in despite the correct syntax. For some reason, the weights seemed to not affect the training loss if retrained again and when inference is run, the model seems to not understand that we have weights from other trainings already loaded in. We ruled out the possibility that the compute_ap method in utils.py, responsible for outputting mAP, precision, and recall, is used incorrectly since the resulting images from inference showed a 100% failure rate.
Discussion
YOLOv5 was the fastest out of any of the other models we compared, and performed the best on our test data based on mAP, precision, and accuracy metrics. Faster R-CNN showed extremely promising results even with half of YOLOv5’s epochs and dataset in which it was still able to detect a fair bit of license plates in each image. From our training and limited GPU resources YOLOv5 is a clear winner however we believe that if we were able to train Faster R-CNN with equal epochs and images Faster R-CNN could perform equally with YOLOv5.
Conclusions
In terms of license plate detection YOLOv5 outperformed the other two models with the resources currently available to us. For a better result to compare these models, we would need a decent GPU resource and time to train these models. There is a possibility that Faster R-CNN and Mask R-CNN could perform on the same level as YOLOv5 if given these resources. Other future applications can be looking into other object detections models to further compare model train times and metrics to see what is the most effective license plate detection and working on Mask R-CNN a little more to figure out the possible problems from using it.
Timeline
Our team’s GANNT Chart can be found here. You may need to sign in to your Georgia Tech Microsoft account for access.
Contribution Table
| Name | Contribution |
|---|---|
| Ricky Lin | Set up meetings, methods, finding/combining datasets, YOLO model training, midterm-report, Mask R-CNN metrics and training, discussion |
| Hung Nyugen | Introduction, problem definition, revisions, finding/combining datasets, midterm-report, Mask R-CNN training and section, conclusion |
| Abdulaziz Memesh | Investigate the Faster R-CNN model and figure out how to run it, look into metrics |
| Saurav Ghosal | Train, validate, and test Faster R-CNN model on custom dataset and wrote background and results of model |
| Sang June Rhee | Finding datasets, data collection, did inference for YOLO and Mask R-CNN model, midterm-report |
References
-
Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2016). Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(1), 142–158. doi:10.1109/TPAMI.2015.2437384 ↩ ↩2 ↩3
-
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr.2016.91 ↩ ↩2
-
Ching. (2021, March 20). Object detection explained: R-CNN - towards data science. Towards Data Science. Retrieved November 13, 2022, from https://towardsdatascience.com/object-detection-explained-r-cnn-a6c813937a76 ↩